# What this PR does
This PR add sync with grafana on requests from terraform
## Which issue(s) this PR fixes
It's needed to fix case when customers want to create team via grafana
terraform provider and use it in the oncall provider without having to
log into Grafana Cloud.
Co-authored-by: Joey Orlando <joey.orlando@grafana.com>
# What this PR does
Fixes the issue when users with the viewer role can't fetch the cloud
connection status, which makes the plugin fail to load for viewers. This
PR makes the cloud connection endpoint use `OTHER_SETTINGS_READ` for
fetching the cloud connection status instead of `OTHER_SETTINGS_WRITE`.
## Checklist
- [x] Tests updated
- [x] `CHANGELOG.md` updated
# What this PR does
This just tweaks the message users get when they try to interact via
slack but haven't connected their profile, it fixes a typo and
streamlines the text.
# What this PR does
Changing query to retrieve alert group in two completely different
queries instead of one with `join`
new queries
```
SELECT alerts_alertreceivechannel.id
FROM alerts_alertreceivechannel
WHERE (alerts_alertreceivechannel.deleted_at IS NULL
AND alerts_alertreceivechannel.organization_id = 8
AND alerts_alertreceivechannel.team_id IS NULL)
SELECT `alerts_alertgroup`.`id`
FROM `alerts_alertgroup`
WHERE (`alerts_alertgroup`.`channel_id` IN (2,33,34,35,36,40,52,59,61,62,63,70,76,89,93,94,03,08,09,10,12,13,16,18,20,22,23,24,26,27,28,30,31,33,34,35,36,40,41,42,43,45,48,53,56,57,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,86,87,88,89,91,93,23,27,29,31,32,33,55,56,57,58,65,69,72,75,81,13,17,20,22,33,34,38,39,41,44,45,46,51,52,55,56,58,59,60,63,68,70,71)
AND NOT `alerts_alertgroup`.`is_archived`
AND NOT `alerts_alertgroup`.`is_archived`
AND `alerts_alertgroup`.`root_alert_group_id` IS NULL
AND ((NOT `alerts_alertgroup`.`silenced`
AND NOT `alerts_alertgroup`.`acknowledged`
AND NOT `alerts_alertgroup`.`resolved`)
OR (`alerts_alertgroup`.`acknowledged`
AND NOT `alerts_alertgroup`.`resolved`))
AND NOT `alerts_alertgroup`.`is_archived`)
ORDER BY `alerts_alertgroup`.`id` DESC
LIMIT 26
```
## Which issue(s) this PR fixes
## Checklist
- [ ] Tests updated
- [ ] Documentation added
- [ ] `CHANGELOG.md` updated
# What this PR does
Changing query to retrieve alert group in two requests instead of one
with `join`
old query:
```
SELECT `alerts_alertgroup`.`id`
FROM `alerts_alertgroup`
INNER JOIN `alerts_alertreceivechannel` ON (`alerts_alertgroup`.`channel_id` = `alerts_alertreceivechannel`.`id`)
WHERE (`alerts_alertreceivechannel`.`organization_id` = 1
AND `alerts_alertreceivechannel`.`team_id` IS NULL
AND NOT `alerts_alertgroup`.`is_archived`
AND NOT `alerts_alertgroup`.`is_archived`
AND `alerts_alertgroup`.`root_alert_group_id` IS NULL
AND ((NOT `alerts_alertgroup`.`silenced`
AND NOT `alerts_alertgroup`.`acknowledged`
AND NOT `alerts_alertgroup`.`resolved`)
OR (`alerts_alertgroup`.`acknowledged`
AND NOT `alerts_alertgroup`.`resolved`))
AND NOT `alerts_alertgroup`.`is_archived`)
ORDER BY `alerts_alertgroup`.`id` DESC
LIMIT 26
```
new query:
```
SELECT "alerts_alertgroup"."id"
FROM "alerts_alertgroup"
WHERE ("alerts_alertgroup"."channel_id" IN
(SELECT U0."id"
FROM "alerts_alertreceivechannel" U0
WHERE (NOT (U0."integration" = maintenance)
AND U0."deleted_at" IS NULL
AND U0."organization_id" = 1
AND U0."team_id" IS NULL))
AND NOT "alerts_alertgroup"."is_archived"
AND NOT "alerts_alertgroup"."is_archived"
AND "alerts_alertgroup"."root_alert_group_id" IS NULL
AND ((NOT "alerts_alertgroup"."silenced"
AND NOT "alerts_alertgroup"."acknowledged"
AND NOT "alerts_alertgroup"."resolved")
OR ("alerts_alertgroup"."acknowledged"
AND NOT "alerts_alertgroup"."resolved"))
AND NOT "alerts_alertgroup"."is_archived")
ORDER BY "alerts_alertgroup"."id" DESC
LIMIT 26
```
## Which issue(s) this PR fixes
## Checklist
- [ ] Tests updated
- [ ] Documentation added
- [ ] `CHANGELOG.md` updated
# What this PR does
Hide direct paging integrations from the web UI. Related to
https://github.com/grafana/oncall/issues/823
## Checklist
- [x] Tests updated
- [ ] Documentation added (N/A)
- [ ] `CHANGELOG.md` updated (N/A)
Slash command needs to be added to slack app manifest:
```
slash_commands:
- command: /escalate
url: https://<oncall-public-url>/slack/interactive_api_endpoint/
description: Create a new alert group escalation
should_escape: false
```
# What this PR does
## Main stuff
- add Python script to populate local Grafana/OnCall setup w/ large
amounts of fake data. Right now the data types that can be generated
are:
- teams and Admin users via the Grafana API (must be synced manually by
going into the UI before going onto the next step)
- Calendar Schedules which have three 8h oncall-shifts, via the OnCall
public API
- fixes `django-debug-toolbar` when being run in `docker-compose`
locally
## Other stuff
- documents how to easily modify the Grafana `docker-compose` container
provisioning configuration
- document solutions for two backend setup related issues encountered
when running the engine/celery workers locally, outside of
`docker-compose`, on an Apple silicon Mac
- fixes small bug in `grafana_plugin.helpers.client.APIClient.call_api`
where it would call `response.json()` for all requests, regardless of
whether or not the response actually contained data or not
- in `engine/settings/dev.py`, properly setup `django-silk` and document
the steps to use it locally
- make it possible to log out debug SQL queries by specifying
`DEV_DEBUG_VIEW_SQL_QUERIES` env var, rather than having to uncomment
out a section of `settings/dev.py`
## Which issue(s) this PR fixes
- Some local setup issues when trying to use `django-silk` and
`django-debug-toolbar`
- Makes it much easier to populate your local setup with a lot of fake
data
- Makes it possible to easily modify your local grafana's provisioning
configuration
## Checklist
- [ ] Tests updated (N/A)
- [ ] Documentation added (N/A)
- [ ] `CHANGELOG.md` updated (N/A)
# What this PR does
Adds an ability to page an escalation chain for a newly created direct
paging alert group using the internal API. Also [adds a forgotten
migration](32fc44e744)
related to the direct paging backend.
Related to https://github.com/grafana/oncall/issues/823
## Checklist
- [x] Tests updated
- [ ] Documentation added (N/A)
- [ ] `CHANGELOG.md` updated (N/A)
Add a dummy step for declare incident button to prevent raising 'Step is
undefined' exception because Slack sends a POST request to the backend
upon clicking a button with a redirect link to Incident.
This pr doesn't change any functionality
# What this PR does
Currently, when a user gets mentioned in an alert group thread and the
user is not in the Slack channel, the Slack bot sends the following to
the channel:
> ⚠️ Tried to ask USER to look at incident. Unfortunately USER is
not in this channel. Please, invite.
This PR changes this behaviour to instead send a direct message to the
user. The message contains a link to the main alert group message in
Slack.
<img width="806" alt="Screenshot 2023-01-17 at 19 25 36"
src="https://user-images.githubusercontent.com/20116910/212996457-02db183f-2041-4998-b743-bd5b6c84b7b5.png">
## Checklist
- [ ] Tests updated (N/A)
- [ ] Documentation added (N/A)
- [x] `CHANGELOG.md` updated
Also changes the default integration used when creating an alert group
for a direct page to a custom manual integration to avoid
conflicts/unexpected behaviors with existing manual alerts.
# What this PR does
Allows messaging backends to be enabled/disabled per organization when
getting a list of available personal notification channels.
## Checklist
- [x] Tests updated
- [ ] Documentation added (N/A)
- [x] `CHANGELOG.md` updated
Check if Grafana Incident is enabled. If it is, add a button with a link
to declare Grafana Incident from Alert group in Slack and on Web.
Co-authored-by: Yulia Shanyrova <yulia.shanyrova@grafana.com>
# What this PR does
This PR added a new parameter (state) into the alert_group public API to
filter the state of the alert groups
## Which issue(s) this PR fixes
https://github.com/grafana/oncall/issues/684
## Checklist
- [x] Tests updated
- [x] Documentation added
- [x] `CHANGELOG.md` updated
Co-authored-by: Vadim Stepanov <vadimkerr@gmail.com>
# What this PR does
Checks the `is_rbac_permissions_enabled` flag differently based on
whether we are dealing with an open-source, or cloud installation:
- for open-source installations, simply continue making a `HEAD` request
to the list RBAC permissions Grafana API endpoint.
- for cloud installations, use the `config` object returned from `GET
/instances/{instance_id}?config=true` and check whether
`instance_info["config"]["feature_toggles"]["accessControlOnCall"] ==
"true"`
## Which issue(s) this PR fixes
Resolves the issue in hosted grafana where when a stack is inactive, the
hosted grafana gateway, returns 200 to the `HEAD` request (which
erroneously sets the `is_rbac_permissions_enabled` flag to `true`)
## Checklist
- [x] Tests updated (N/A)
- [ ] Documentation added
- [x] `CHANGELOG.md` updated
# What this PR does
It introduces soft-delete of organization, since grafana stacks are
soft-deleted too. Also, we had a problem with deleting orgs with large
amounts of alerts, so soft-deletion will fix this problem. I think, that
problem of cleaning alerts of deleted orgs should be solved as a part of
alert retention
# What this PR does
Makes Telegram integration consistent with the rest of the system so it
uses the word "alert group" instead of "incident" when referring to
alert groups.
## Checklist
- [x] Tests updated
- [ ] Documentation added (N/A)
- [x] `CHANGELOG.md` updated
This PR adds an endpoint returning a schedule quality score, overloaded
users and comments on the existing issues (e.g. balance issues or gaps).
## Limitations
- Since working hours editor is not implemented yet, there are only two
scores taken into account: balance score and a score representing the
ratio of time when someone is on-call to the whole time period.
- Time period is now set to be constant (90 days from today), so **in
some cases the results will be inaccurate** (when rotations don't align
with the time period)
- It only takes primary rotations into account (overrides are ignored)
## Usage
`GET /api/internal/v1/schedules/<pk>/quality?date=<TOMORROW_DATE>`
Note that `date` should be tomorrow date, because we can only be sure
about changing tomorrow's shifts (some of the shifts for current day
could be "deleted" but still show up in the UI).
## Example response
```json
{
"total_score": 90,
"comments": ["Schedule has no gaps", "Schedule is well-balanced, but still can be improved"],
"overloaded_users": ["USSZ5WRH2CUA9", "U74XJZSSQGBIH"]
}
```
Issue: #118
# What this PR does
With the addition of tighter controls on jinja templates handle
exceptions while rendering group data as follows:
- Title will cache error message as title and display to user and the
error will be logged
- Group distinction will be left as None and the error will be logged
- Is resolve signal will be treated as False and the error will be
logged
- Is acknowledge signal will be treated as False and the error will be
logged
## Which issue(s) this PR fixes
https://github.com/grafana/oncall-private/issues/1542
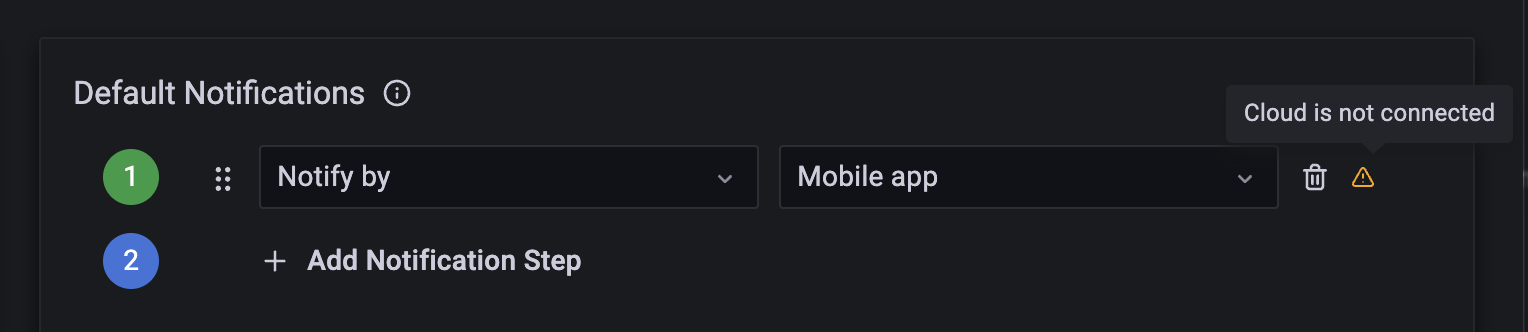
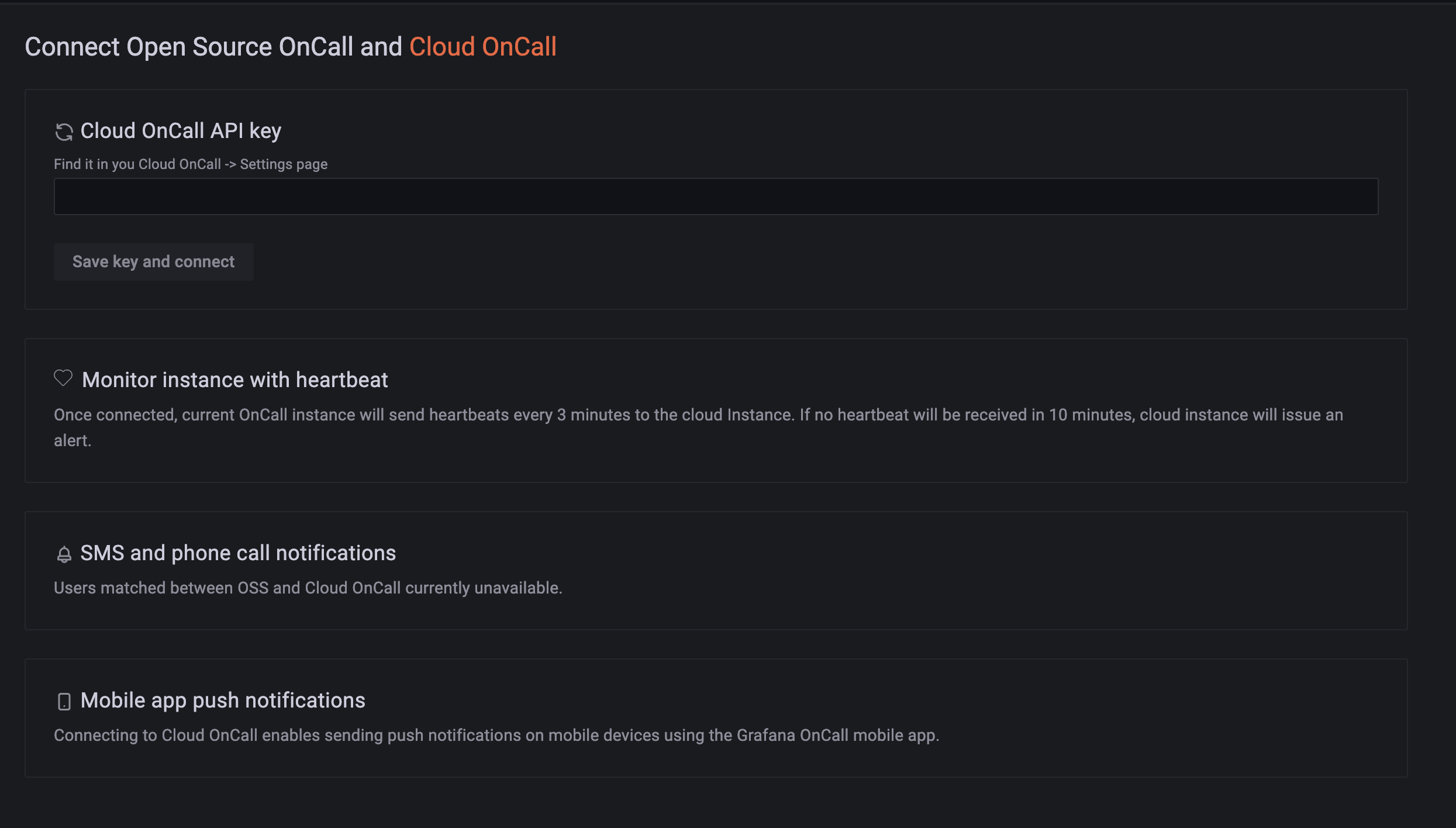
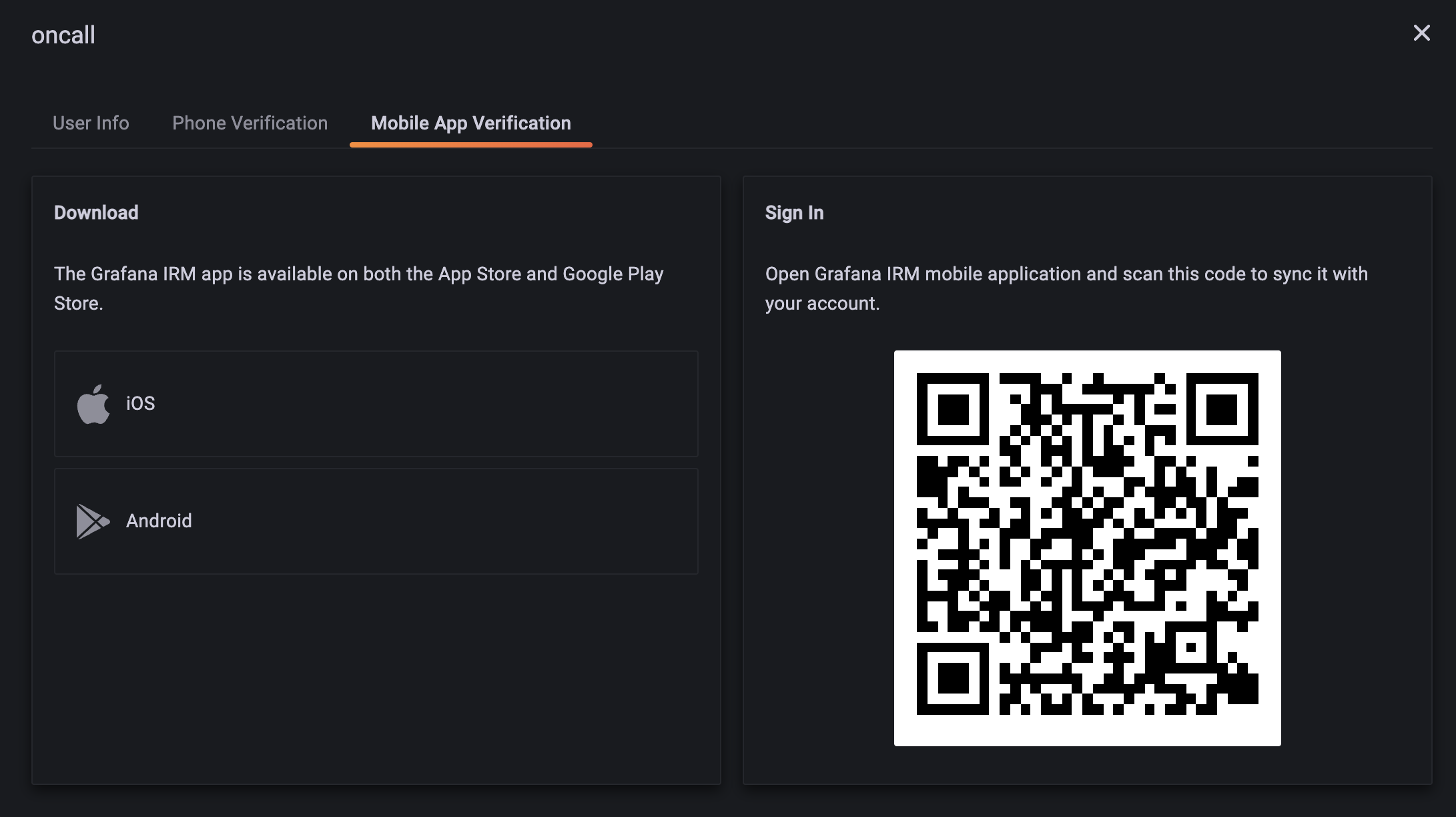
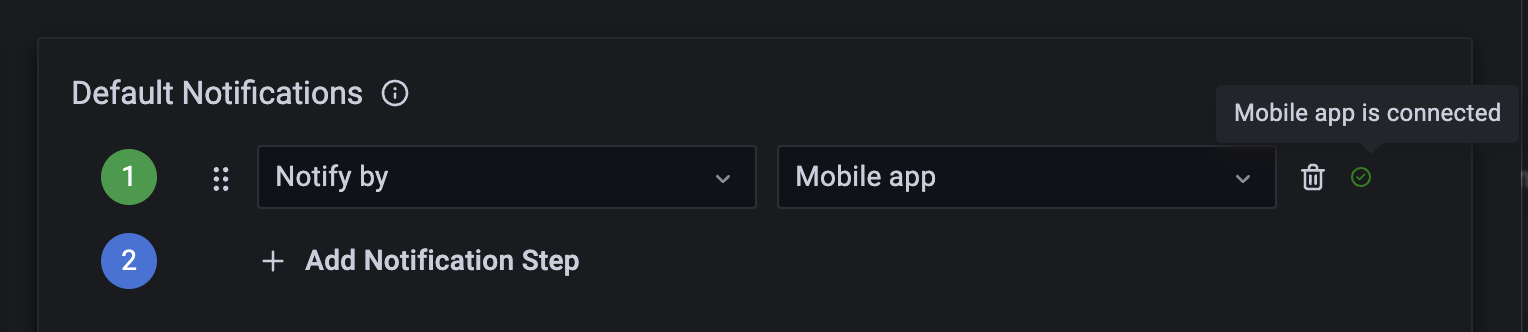
- swaps out `django-push-notifications` for
[`fcm-django`](https://github.com/grafana/fcm-django). Again.. this is a
fork of the parent repo for exactly the same reason.. the migrations
point to `auth_user` without letting us use our own user model, this has
been patched in the `grafana` fork. The reason why we are using
`fcm-django` vs `django-push-notifications` is that the latter does not
support the new FCM API, only the "legacy" API. The legacy FCM API does
not support certain push notification settings that we would like to
use.
- modifies the iOS/Android specific push notification settings
- adds a `flower` pod in the `docker-compose-developer.yml`, useful for
debugging tasks locally
- sets the mobile app verification token TTL to 5 minutes when
developing locally. The default of 1 minute makes working with device
emulators really tricky..
This PR also swaps out the base image in `engine/Dockerfile` from
`python:3.9-alpine3.16` to `python:3.9-slim-buster`.
As to why.. in short, with the introduction of the `fcm-django` library
there is now a peer-dependency on
[`grpcio`](https://github.com/grpc/grpc) (which is used by
`firebase_admin`.. which I am using in this PR to interact directly with
Firebase Cloud Messaging (FCM)). `grpcio` does not publish wheels (read:
compiled binaries) for the Alpine distro. It does publish wheels for
Debian and hence `pip install -r requirements.txt` does not need to
build this library from the source distribution.
This is a [known
"issue"](https://github.com/grpc/grpc/issues/22815#issuecomment-1107874367)
and the recommended solution in the community is to.. not use alpine.
These were the numbers, when building the image locally, in terms of
image size and build time:
| | Local image size (uncompressed | Build time (may differ based on
your network speed) |
| ------------------------- | -------------------------------------- |
---------- |
| `python:3.9-alpine3.16` | 785MB | 320s |
| `python:3.9-slim-buster` | 1.05GB | 90s |
Co-authored-by: Salvatore Giordano <salvatoregiordanoo@gmail.com>
- removes APNS support
- changes the `django-push-notification` library from the `iskhakov`
fork to the [`grafana`
fork](https://github.com/grafana/django-push-notifications). This new
fork basically just patches an issue which affected the database
migrations of this django app (previously the library would not respect
the `USER_MODEL` setting when creating its tables and would instead
reference the `auth_user` table.. which we don't want)
- add `--no-cache` flag to the `make build` command
**NOTE**
A migration should be applied as follows:
```bash
# remove the four push_notifications tables, which have improper foreign key references
python manage.py migrate push_notifications zero
# recreate the tables with the proper foreign key references
python manage.py migrate
```
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}