# What this PR does
First draft of documentation. @alyssawada please use it as a starting
point :)
## Which issue(s) this PR fixes
## Checklist
- [ ] Tests updated
- [x] Documentation added
- [ ] `CHANGELOG.md` updated
---------
Co-authored-by: alyssa wada <alyssa.wada@grafana.com>
Co-authored-by: Joey Orlando <joey.orlando@grafana.com>
Co-authored-by: Alyssa Wada <101596687+alyssawada@users.noreply.github.com>
Co-authored-by: Vadim Stepanov <vadimkerr@gmail.com>
# What this PR does
Remove checks for `mobile_app_settings` DynamicSetting, so changing
`FEATURE_MOBILE_APP_INTEGRATION_ENABLED` is enough for toggling the
mobile app backend (aka remove per-org feature flag)
Co-authored-by: Joey Orlando <joey.orlando@grafana.com>
# What this PR does
Fixes an issue when a local dev setup becomes extremely slow.
- Set `DEBUG` and `SILK_PROFILER_ENABLED` to `False` by default + add
utility make commands to toggle it
- Use `uwsgi` instead of Django's built-in `runserver` for local dev
setup
- Limit Celery concurrency to 3 for local dev setup (previously was 20,
used >1GB RAM on my machine)
---------
Co-authored-by: Joey Orlando <joey.orlando@grafana.com>
# What this PR does
This PR adds same approach as introduced
[here](https://github.com/grafana/oncall/pull/1236) to all alert and
alertgroup endpoints
## Which issue(s) this PR fixes
## Checklist
- [ ] Tests updated
- [ ] Documentation added
- [ ] `CHANGELOG.md` updated
---------
Co-authored-by: Joey Orlando <joey.orlando@grafana.com>
# What this PR does
This is a minor refactor before implementing
https://github.com/grafana/oncall-private/issues/1558.
Additionally, it cleans up a few spots where we do this:
```
# Re-take in case we are in the readonly db context.
```
We currently don't read anything from a read-only database, so this
should be not necessary.
## Checklist
- [x] Tests updated
- [ ] Documentation added (N/A)
- [ ] `CHANGELOG.md` updated (N/A)
Related to #1119
It also adds a shortcut to filter current user's related alert groups
(alert groups user was notified by, or in which user participated). Make
the filter visible by default, with a false value.
# What this PR does
Make direct paging internal API endpoint return an alert group ID.
## Which issue(s) this PR fixes
Related to https://github.com/grafana/oncall/issues/823
## Checklist
- [x] Tests updated
# What this PR does
This PR caches the field `render_for_web` with lifetime 1 day and cache
becomes invalid if it was created before
* last alert received
* template changed
## Which issue(s) this PR fixes
## Checklist
- [ ] Tests updated
- [ ] Documentation added
- [ ] `CHANGELOG.md` updated
Fixes issue when there are more than 100 users to be listed in the
direct pagination responders select. Alternatively we should consider
moving to an `external_select` block later.
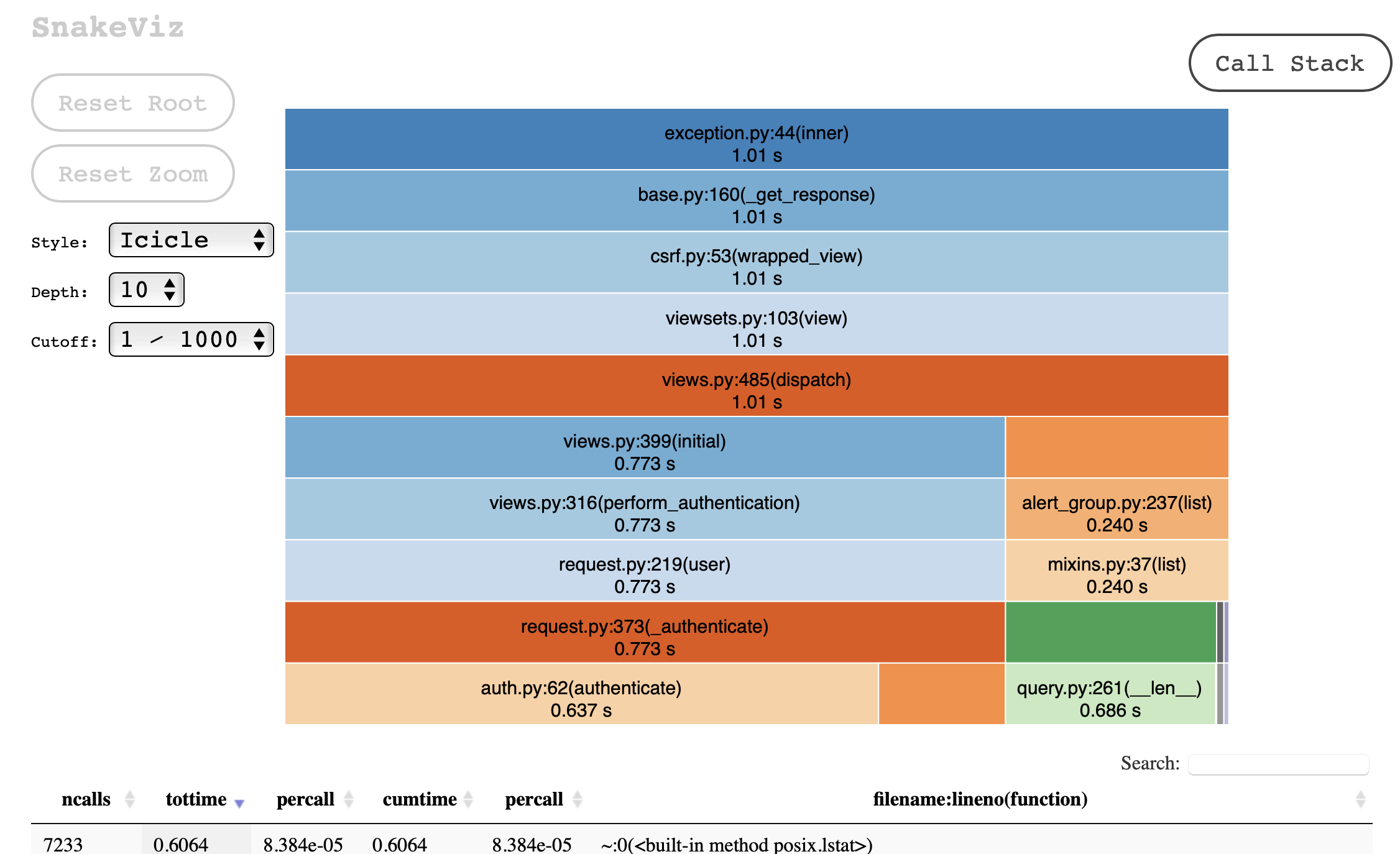
# What this PR does
Fixes slow internal`GET /schedules` endpoints. Using the fake-data
generation script in #1128, I generated 65 calendar schedules in my
local setup. This resulted in the following endpoint performance:

The responses which show ~76 queries were run on the latest `dev`
branch. Responses w/ ~26 queries were run on this branch.
Additionally:
- add typing to a few methods in `apps/schedules/ical_utils.py`
- document `apps/api/permissions/__init__.py:user_is_authorized`
function
## Which issue(s) this PR fixes
https://github.com/grafana/oncall-private/issues/1552
## Checklist
- [ ] Tests updated
- [ ] Documentation added
- [ ] `CHANGELOG.md` updated
Co-authored-by: Vadim Stepanov <vadimkerr@gmail.com>
**What this PR does**:
- Keep grafana version on create/update contact points to avoid multiple
requests to alerting
- Add retry limit on create contact point async
- Fix bugs related on create contact point
- Update logs on create/update contact point, make them more clear
- Avoid unnecessary requests to Grafana Alerting
# What this PR does
This PR adds a shortcut in the plugin synchronisation process, so the
existing users will be able login without waiting for the sync task.
Every request still starts the background synchronisation task, to be
able to propagate the organisation changes faster than periodic task. It
means that we don't necessarily need "force reload" button in the
interface.
For all the other cases (user does not exist, organisation token "not
ok", etc) process remains same - plugin will show "Initialising
plugin..." until the background task in successfully completed
Co-authored-by: Joey Orlando <joey.orlando@grafana.com>
# What this PR does
Make so there's no need to populate `mobile_app_settings` DynamicSetting
when using the OSS license to turn on the mobile app backend.
# What this PR does
This PR add sync with grafana on requests from terraform
## Which issue(s) this PR fixes
It's needed to fix case when customers want to create team via grafana
terraform provider and use it in the oncall provider without having to
log into Grafana Cloud.
Co-authored-by: Joey Orlando <joey.orlando@grafana.com>
# What this PR does
Fixes the issue when users with the viewer role can't fetch the cloud
connection status, which makes the plugin fail to load for viewers. This
PR makes the cloud connection endpoint use `OTHER_SETTINGS_READ` for
fetching the cloud connection status instead of `OTHER_SETTINGS_WRITE`.
## Checklist
- [x] Tests updated
- [x] `CHANGELOG.md` updated
# What this PR does
This just tweaks the message users get when they try to interact via
slack but haven't connected their profile, it fixes a typo and
streamlines the text.
# What this PR does
Changing query to retrieve alert group in two completely different
queries instead of one with `join`
new queries
```
SELECT alerts_alertreceivechannel.id
FROM alerts_alertreceivechannel
WHERE (alerts_alertreceivechannel.deleted_at IS NULL
AND alerts_alertreceivechannel.organization_id = 8
AND alerts_alertreceivechannel.team_id IS NULL)
SELECT `alerts_alertgroup`.`id`
FROM `alerts_alertgroup`
WHERE (`alerts_alertgroup`.`channel_id` IN (2,33,34,35,36,40,52,59,61,62,63,70,76,89,93,94,03,08,09,10,12,13,16,18,20,22,23,24,26,27,28,30,31,33,34,35,36,40,41,42,43,45,48,53,56,57,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,86,87,88,89,91,93,23,27,29,31,32,33,55,56,57,58,65,69,72,75,81,13,17,20,22,33,34,38,39,41,44,45,46,51,52,55,56,58,59,60,63,68,70,71)
AND NOT `alerts_alertgroup`.`is_archived`
AND NOT `alerts_alertgroup`.`is_archived`
AND `alerts_alertgroup`.`root_alert_group_id` IS NULL
AND ((NOT `alerts_alertgroup`.`silenced`
AND NOT `alerts_alertgroup`.`acknowledged`
AND NOT `alerts_alertgroup`.`resolved`)
OR (`alerts_alertgroup`.`acknowledged`
AND NOT `alerts_alertgroup`.`resolved`))
AND NOT `alerts_alertgroup`.`is_archived`)
ORDER BY `alerts_alertgroup`.`id` DESC
LIMIT 26
```
## Which issue(s) this PR fixes
## Checklist
- [ ] Tests updated
- [ ] Documentation added
- [ ] `CHANGELOG.md` updated
# What this PR does
Changing query to retrieve alert group in two requests instead of one
with `join`
old query:
```
SELECT `alerts_alertgroup`.`id`
FROM `alerts_alertgroup`
INNER JOIN `alerts_alertreceivechannel` ON (`alerts_alertgroup`.`channel_id` = `alerts_alertreceivechannel`.`id`)
WHERE (`alerts_alertreceivechannel`.`organization_id` = 1
AND `alerts_alertreceivechannel`.`team_id` IS NULL
AND NOT `alerts_alertgroup`.`is_archived`
AND NOT `alerts_alertgroup`.`is_archived`
AND `alerts_alertgroup`.`root_alert_group_id` IS NULL
AND ((NOT `alerts_alertgroup`.`silenced`
AND NOT `alerts_alertgroup`.`acknowledged`
AND NOT `alerts_alertgroup`.`resolved`)
OR (`alerts_alertgroup`.`acknowledged`
AND NOT `alerts_alertgroup`.`resolved`))
AND NOT `alerts_alertgroup`.`is_archived`)
ORDER BY `alerts_alertgroup`.`id` DESC
LIMIT 26
```
new query:
```
SELECT "alerts_alertgroup"."id"
FROM "alerts_alertgroup"
WHERE ("alerts_alertgroup"."channel_id" IN
(SELECT U0."id"
FROM "alerts_alertreceivechannel" U0
WHERE (NOT (U0."integration" = maintenance)
AND U0."deleted_at" IS NULL
AND U0."organization_id" = 1
AND U0."team_id" IS NULL))
AND NOT "alerts_alertgroup"."is_archived"
AND NOT "alerts_alertgroup"."is_archived"
AND "alerts_alertgroup"."root_alert_group_id" IS NULL
AND ((NOT "alerts_alertgroup"."silenced"
AND NOT "alerts_alertgroup"."acknowledged"
AND NOT "alerts_alertgroup"."resolved")
OR ("alerts_alertgroup"."acknowledged"
AND NOT "alerts_alertgroup"."resolved"))
AND NOT "alerts_alertgroup"."is_archived")
ORDER BY "alerts_alertgroup"."id" DESC
LIMIT 26
```
## Which issue(s) this PR fixes
## Checklist
- [ ] Tests updated
- [ ] Documentation added
- [ ] `CHANGELOG.md` updated
# What this PR does
Hide direct paging integrations from the web UI. Related to
https://github.com/grafana/oncall/issues/823
## Checklist
- [x] Tests updated
- [ ] Documentation added (N/A)
- [ ] `CHANGELOG.md` updated (N/A)
Slash command needs to be added to slack app manifest:
```
slash_commands:
- command: /escalate
url: https://<oncall-public-url>/slack/interactive_api_endpoint/
description: Create a new alert group escalation
should_escape: false
```
# What this PR does
This PR moves silk profiler under the settings flag which can be
configured with env vars. It will allow us to enable silk on the
clusters, e.g. dev
## Which issue(s) this PR fixes
## Checklist
- [ ] Tests updated
- [ ] Documentation added
- [ ] `CHANGELOG.md` updated
# What this PR does
## Main stuff
- add Python script to populate local Grafana/OnCall setup w/ large
amounts of fake data. Right now the data types that can be generated
are:
- teams and Admin users via the Grafana API (must be synced manually by
going into the UI before going onto the next step)
- Calendar Schedules which have three 8h oncall-shifts, via the OnCall
public API
- fixes `django-debug-toolbar` when being run in `docker-compose`
locally
## Other stuff
- documents how to easily modify the Grafana `docker-compose` container
provisioning configuration
- document solutions for two backend setup related issues encountered
when running the engine/celery workers locally, outside of
`docker-compose`, on an Apple silicon Mac
- fixes small bug in `grafana_plugin.helpers.client.APIClient.call_api`
where it would call `response.json()` for all requests, regardless of
whether or not the response actually contained data or not
- in `engine/settings/dev.py`, properly setup `django-silk` and document
the steps to use it locally
- make it possible to log out debug SQL queries by specifying
`DEV_DEBUG_VIEW_SQL_QUERIES` env var, rather than having to uncomment
out a section of `settings/dev.py`
## Which issue(s) this PR fixes
- Some local setup issues when trying to use `django-silk` and
`django-debug-toolbar`
- Makes it much easier to populate your local setup with a lot of fake
data
- Makes it possible to easily modify your local grafana's provisioning
configuration
## Checklist
- [ ] Tests updated (N/A)
- [ ] Documentation added (N/A)
- [ ] `CHANGELOG.md` updated (N/A)
# What this PR does
Adds an ability to page an escalation chain for a newly created direct
paging alert group using the internal API. Also [adds a forgotten
migration](32fc44e744)
related to the direct paging backend.
Related to https://github.com/grafana/oncall/issues/823
## Checklist
- [x] Tests updated
- [ ] Documentation added (N/A)
- [ ] `CHANGELOG.md` updated (N/A)
Add a dummy step for declare incident button to prevent raising 'Step is
undefined' exception because Slack sends a POST request to the backend
upon clicking a button with a redirect link to Incident.
This pr doesn't change any functionality
# What this PR does
Currently, when a user gets mentioned in an alert group thread and the
user is not in the Slack channel, the Slack bot sends the following to
the channel:
> ⚠️ Tried to ask USER to look at incident. Unfortunately USER is
not in this channel. Please, invite.
This PR changes this behaviour to instead send a direct message to the
user. The message contains a link to the main alert group message in
Slack.
<img width="806" alt="Screenshot 2023-01-17 at 19 25 36"
src="https://user-images.githubusercontent.com/20116910/212996457-02db183f-2041-4998-b743-bd5b6c84b7b5.png">
## Checklist
- [ ] Tests updated (N/A)
- [ ] Documentation added (N/A)
- [x] `CHANGELOG.md` updated
Also changes the default integration used when creating an alert group
for a direct page to a custom manual integration to avoid
conflicts/unexpected behaviors with existing manual alerts.
# What this PR does
Allows messaging backends to be enabled/disabled per organization when
getting a list of available personal notification channels.
## Checklist
- [x] Tests updated
- [ ] Documentation added (N/A)
- [x] `CHANGELOG.md` updated
Check if Grafana Incident is enabled. If it is, add a button with a link
to declare Grafana Incident from Alert group in Slack and on Web.
Co-authored-by: Yulia Shanyrova <yulia.shanyrova@grafana.com>
# What this PR does
This PR added a new parameter (state) into the alert_group public API to
filter the state of the alert groups
## Which issue(s) this PR fixes
https://github.com/grafana/oncall/issues/684
## Checklist
- [x] Tests updated
- [x] Documentation added
- [x] `CHANGELOG.md` updated
Co-authored-by: Vadim Stepanov <vadimkerr@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}