# What this PR does
Adds docs & logo for AppDynamics integration.
Main PR in private repo:
https://github.com/grafana/oncall-private/pull/1790.
## Which issue(s) this PR fixes
https://github.com/grafana/oncall-private/issues/1621
## Checklist
- [x] Unit, integration, and e2e (if applicable) tests updated
- [x] Documentation added (or `pr:no public docs` PR label added if not
required)
- No changelog (AppDynamics integration will be only available in cloud)
# What this PR does
https://www.loom.com/share/18cc445117de4895a10892d56c7d3699
In preparation to upgrade our cloud databases, this PR makes some minor
changes which, after testing locally, allowed the `POST
/<integration_type>/<alert_channel_key>` endpoints to successfully
receive incoming alerts and queue the celery tasks.
I've tested all of the defined `POST
/integrations/v1/<integration_type>/<alert_channel_key>` endpoints by
sending `POST` requests to an integrations' URL while the MySQL database
was down, bringing the database back up, and ensuring the alerts were
created.
## Some other findings
- the integration heartbeat endpoints will not work as we interact w/
the database to persist the incoming heartbeat instance
- if the integration was created in the last 180 seconds, incoming
alerts will fail due to the way we cache the integration IDs
([code](https://github.com/grafana/oncall/blob/dev/engine/apps/integrations/mixins/alert_channel_defining_mixin.py#L47-L50))
- The `create_alert` celery task is set to `max_retries=None` and
`retry_backoff=True`. This means that the queued tasks will continue
retrying forever w/ an exponential backoff, until the alerts can be
created in the database (ie. when the database is back online).
## Checklist
- [ ] Unit, integration, and e2e (if applicable) tests updated (N/A)
- [ ] Documentation added (or `pr:no public docs` PR label added if not
required) (N/A)
- [ ] `CHANGELOG.md` updated (or `pr:no changelog` PR label added if not
required) (N/A)
# What this PR does
There was an unnecessary indentation in the `rules:` key which made it
invalid YAML.
Also replaced the mentions to Amixr with Grafana OnCall, used some
`<code>` tags and reworded some sentences.
Also removed the anchor tag from the webhook link: we don't want people
to follow that in their browser, we want them to copy it
## Result screenshot
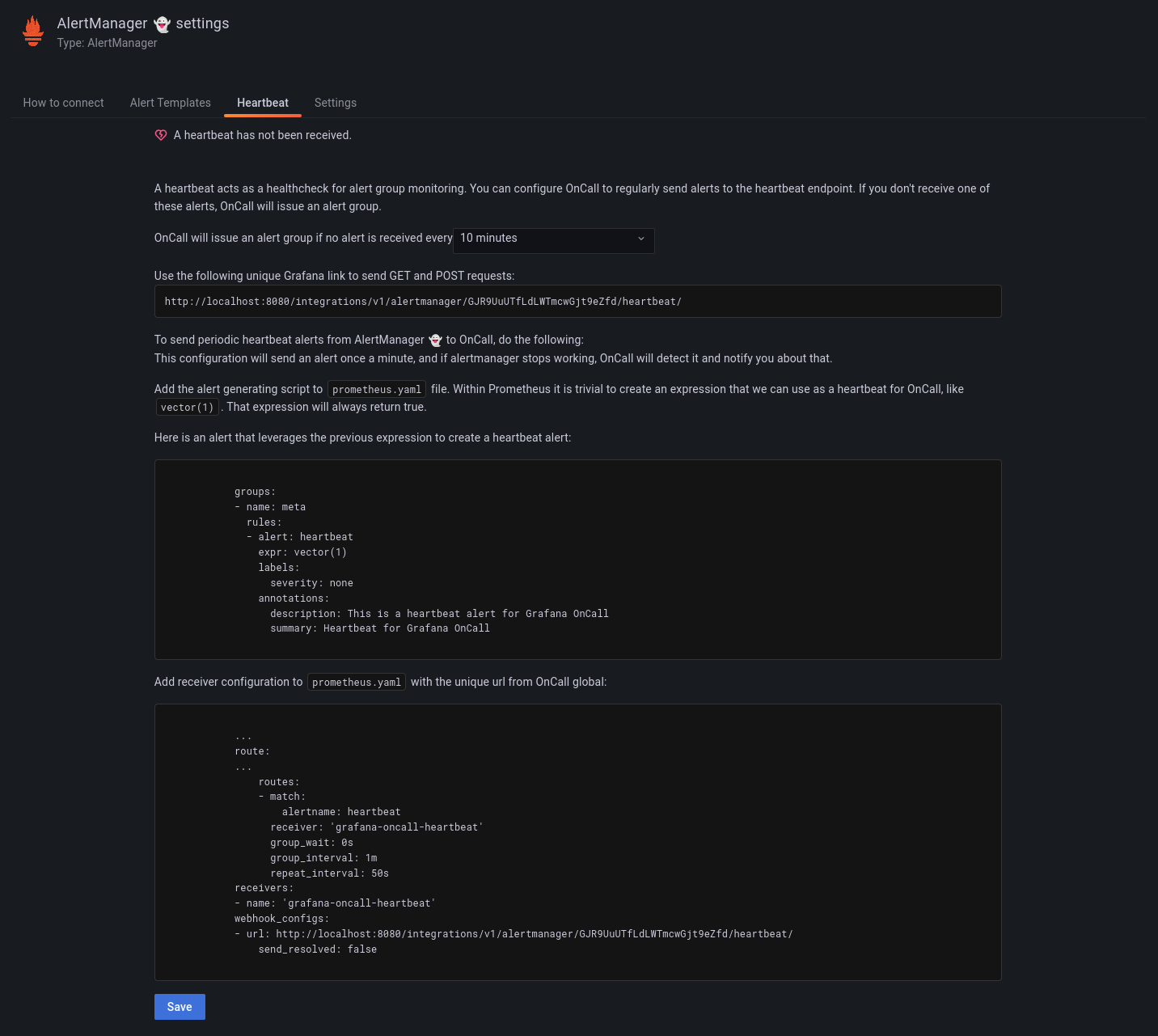
## Which issue(s) this PR fixes
## Checklist
- [ ] Unit, integration, and e2e (if applicable) tests updated
- [ ] Documentation added (or `pr:no public docs` PR label added if not
required)
- [ ] `CHANGELOG.md` updated (or `pr:no changelog` PR label added if not
required)
---------
Signed-off-by: Oleg Zaytsev <mail@olegzaytsev.com>
Co-authored-by: Joey Orlando <joey.orlando@grafana.com>
# What this PR does
Add docs & logo for Zendesk integration. Main PR in private repo:
https://github.com/grafana/oncall-private/pull/1772
## Which issue(s) this PR fixes
https://github.com/grafana/oncall-private/issues/1627
## Checklist
- [x] Unit, integration, and e2e (if applicable) tests updated
- [x] Documentation added (or `pr:no public docs` PR label added if not
required)
- [x] No changelog (Zendesk integration will be only available in cloud)
# What this PR does
Add docs & logo for Jira integration. Main PR in private repo:
https://github.com/grafana/oncall-private/pull/1769
## Which issue(s) this PR fixes
https://github.com/grafana/oncall-private/issues/1620
## Checklist
- [x] Unit, integration, and e2e (if applicable) tests updated
- [x] Documentation added (or `pr:no public docs` PR label added if not
required)
- [x] No changelog (Jira integration will be only available in cloud)
# What this PR does
This PR set the limit so that workers won't attempt to autoresolve too
big alertmanager alert groups.
## Which issue(s) this PR fixes
## Checklist
- [ ] Unit, integration, and e2e (if applicable) tests updated
- [ ] Documentation added (or `pr:no public docs` PR label added if not
required)
- [ ] `CHANGELOG.md` updated (or `pr:no changelog` PR label added if not
required)
This PR add Inbound Email integration.
It designed to support some variety of ESPs, but in prod we will use
Mailgun, so locally I tested it only with mailgun ESP.
**Important:**
To make it work on different clusters I'm planning to provide different
email domains for different regions, like ....@us.oncall.grafana.net,
...@eu.oncall.grafana.net
---------
Co-authored-by: Innokentii Konstantinov <innokenty.konstantinov@grafana.com>
# What this PR does
When an organization is migrated to a different cluster it has it's
`migration_destination_slug` set for redirection purposes but it also
needs to be deleted so scheduled tasks for it do not run in the old
cluster. By changing the order so moved has precedence over deleted API
calls will be correctly redirected for moved organizations while the
organization is still considered deleted to suppress tasks that are no
longer needed in the old cluster.
## Which issue(s) this PR fixes
## Checklist
- [ ] Tests updated
- [ ] Documentation added
- [ ] `CHANGELOG.md` updated
# What this PR does
This PR cleanup ScenarioStep. It's needed to simplify moving Slack to
the messaging backends in future.
1. Introduce AlertGroupSlackService to move logic from ScenarioStep.
Also it allowed to get rid of importing ScenarioSteps in the code not
related to processing of slack callbacks.
2. Remove tags from ScenarioSteps, they are unused.
3. Remove ScenarioStep.dispatch method. It just was calling
ScenarioStep.process_scenario.
4. Remove "action" param from process_scenario, it was unused.
5. Remove creation of SlackActionRecord on handling SlackEvents. We are
not using it, but it generates INSERT query on most of the user-slack
interactions.
6. Remove "random_prefix_for_routing" from ScenarioStep, it was unused.
## Which issue(s) this PR fixes
## Checklist
- [ ] Tests updated
- [ ] Documentation added
- [ ] `CHANGELOG.md` updated
---------
Co-authored-by: Joey Orlando <joey.orlando@grafana.com>
Also changes the default integration used when creating an alert group
for a direct page to a custom manual integration to avoid
conflicts/unexpected behaviors with existing manual alerts.
# What this PR does
It introduces soft-delete of organization, since grafana stacks are
soft-deleted too. Also, we had a problem with deleting orgs with large
amounts of alerts, so soft-deletion will fix this problem. I think, that
problem of cleaning alerts of deleted orgs should be solved as a part of
alert retention
* remove email verification related code
* remove email verification related code
* remove sendgrid callback
* remove sendgrid related code
* remove sendgrid related code
* rename sendgrid app to email
* remove email from built-in channels
* remove email from built-in channels
* remove email from built-in channels
* add email backend: https://github.com/grafana/oncall/pull/50
* add email templater
* add email templater
* convert md to html
* add email settings to live settings
* use task to send email, handle some exceptions to create logs
* remove ERROR_NOTIFICATION_MAIL_DELIVERY_FAILED usage
* add email limit logic
* fix tests
* add docs
* remove old email templates
* remove old email templates
* add template_fields to messaging backend
* add messaging backends templates to public api
* add comment for deprecated fields
* fix test
* fix tests
* disable email by default
* don't retry on SMTPException and TimeoutError
* add tests
* bring email back to public api docs
* return ERROR_NOTIFICATION_MAIL_LIMIT_EXCEEDED
* make template_fields tuple
* build_subject_and_title -> build_subject_and_message
* add one more comment about template deprecation
* use 8 as backend id
* add comment about gaierror and BadHeaderError
* add comment on importing in notify_user_async
* edit oss docs
* add libs for celery + redis
* move redis & cache config to settings/base.py
* move rmq & celery config to settings/base.py
* BROKER -> BROKER_TYPE
* allow multiple database types
* flake8
* add sqlite db creation to dockerfile
* fix ci
* fix ci
* debug
* remove some defaults
* remove prints
* use local memory as cache on ci
* debug
* add DATABASE_DEFAULTS
* add ci test for sqlite + redis
* add ci test for sqlite + redis
* add ci test for sqlite + redis
* debug
* add redis healthcheck
* fix sqlite
* fix dev settings
* refactor dev settings
* tweak ci settings
* clear cache properly between tests
* move db and broker types to constants
* add librabbitmq deps
* use amqp instead of librabbitmq
* Log (failed) attempt to notify a user with viewer role
* Remove https:// prefix from BASE_URL docker env var
* Fix cloud heartbeat name
* Polishing telegram
* Update docker-compose.yml
* Update plugin README (#48)
* Update README and screenshot, remove plop for build info since version is now displayed prominently
* Sign build
Co-authored-by: Michael Derynck <michael.derynck@grafana.com>
* Build actions (#38)
* Drone, github action changes
* Minor version updates
* Update frontend dependencies
* Re-enable unit test
Co-authored-by: Michael Derynck <michael.derynck@grafana.com>
* Revert stylelint version (#52)
* Revert stylelint version
* Build plugin as well as lint
* Build in previous step
Co-authored-by: Michael Derynck <michael.derynck@grafana.com>
* Update screenshot (#53)
Co-authored-by: Michael Derynck <michael.derynck@grafana.com>
Co-authored-by: Matias Bordese <mbordese@gmail.com>
Co-authored-by: Matvey Kukuy <Matvey-Kuk@users.noreply.github.com>
Co-authored-by: Innokentii Konstantinov <innokenty.konstantinov@grafana.com>
Co-authored-by: Matvey Kukuy <matvey@amixr.io>
Co-authored-by: Michael Derynck <michael.derynck@grafana.com>
{kind=link}